
It is Sunday morning. Just a day before a short vacation in a wellness hotel. I wake up and take a look at my phone. A bunch of alerts from Netdata about BTRFS corruption errors. Good morning! 🌅
So, I have two raids on my server. One slow raid with 4 x 12 TB HDDs and one fast raid with 2 x 500GB SSDs.
One of the SSDs failed. This is the first time in my life to lose a disk. Anyway, it was a used Intel enterprise SSD which I got from eBay a couple of years ago. I was wondering when this would fail. I used this to create some Chia a couple of years ago.
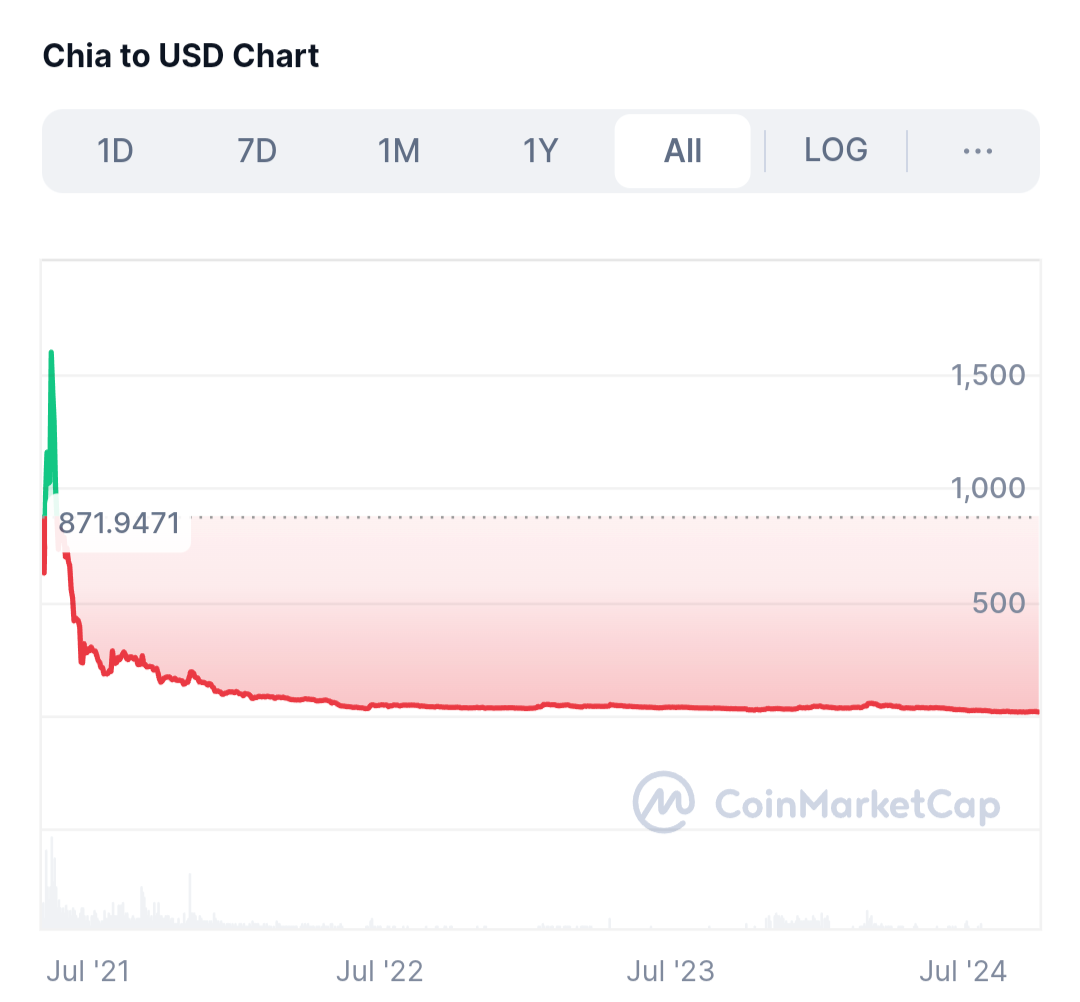
As you can see: it did not pay out 😆. I still have the seed and might have a couple of Chia. Another time though. I do not even know where to import them.
So, why did the SSD die? I wanted to create my own Bitcoin node and lighting thing. I plan to move some bitcoin over the lighting network from a web-based wallet to a new hardware wallet I got. As of my understanding, you need a full node for lightning transactions. So lots of writing because a full node needs about 500GB.
Problem: During that time one SSD died and the raid filled up at the same time. I was under the impression that 300GB would be enough. However, it was a bit over 500GB that needed to be written. So it's full and broken. Nice!
Trying to fix the raid
I checked the dmesg log and found errors from one of the SSDs in the raid.

The name ssd_raid-2 is the name of my LUKS container for that SSD. To look up the device and the corresponding serial number I used lsblk again:
andrej@nas:~$ lsblk -o name,serial,uuid,size
NAME SERIAL UUID
sdf BTWA615000UP480FGN f4845b75-aba4-4bfe-845c-b647b9184456 447.1G
└─ssd_raid-1 cc6d1c26-d69e-4c75-b0cd-3edddf3ffb00 447.1G
Now, I could find the physical SSD on my server with the serial number. I grabbed a spare HDD I had lying around and showed it to the side. My SATA power cables were not long enough for the cage. The shelf it is.

After plugging everything in I rebooted the machine. It did not come back...
A little Side Quest - PiKVM not working
The machine was not coming back. 😮💨 Okay, let's go to the PiKVM. First I forgot to plug in the network cable. That was fixed quickly.
Then I saw the UEFI/BIOS on the PiKVM. But as soon as I tried to interact with the UEFI the screen looked weird:
After a quick Google search, I found the issue is the board compatibility with PiKVM. Luckily there was a workaround available in the PiKVM documentation.
Okay, after updating PiKVM and adding the new EDID file I could see the output before the UEFI started:
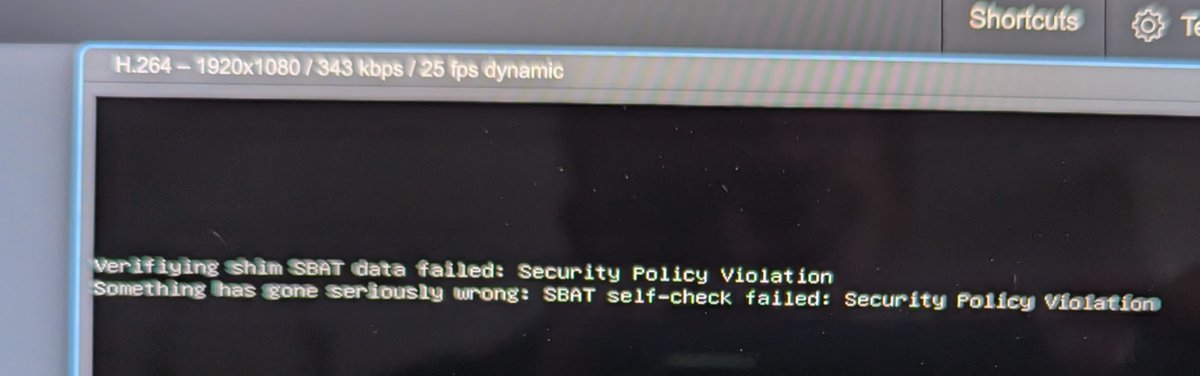
Verifying shim SBAT data failed: Security Policay Violation
something has gone seriously wrong: SBAT self-check failed: Security Policay Violation
Ah yes, secure boot on my Proxmox host below the VM which is my NAS. Turning off Secure Boot for now on the UEFI solved it for now.
Not sure why it has complained yet. Maybe the new HDD? Maybe installing the Bitcoin software or I did an update with new Kernels? Not sure yet. I am new to Secure Boot.
Sidequest accomplished. Back to BTRFS.
Fixing the SSD Raid
I created a subvolume @bitcoin for the Bitcoin content. So I figured, I could just delete that subvolume to gain some space for the rescue operation. For some reason a btrfs subevolume delete @bitcoin did delete the subvolume but did not free up any space.
Okay, then let's replace the broken disk with my HDD.
I would have added the HDD to the raid setup and removed the SSD. But I did some research and it turn out a btrfs replace is the better way of doing this operation. Thanks to this article:
After replacing I did start a rebalance. That kind of worked, but the space was not recovered even though a full subvolume with the most data was deleted.
I thought a scrub might help and indeed it did!
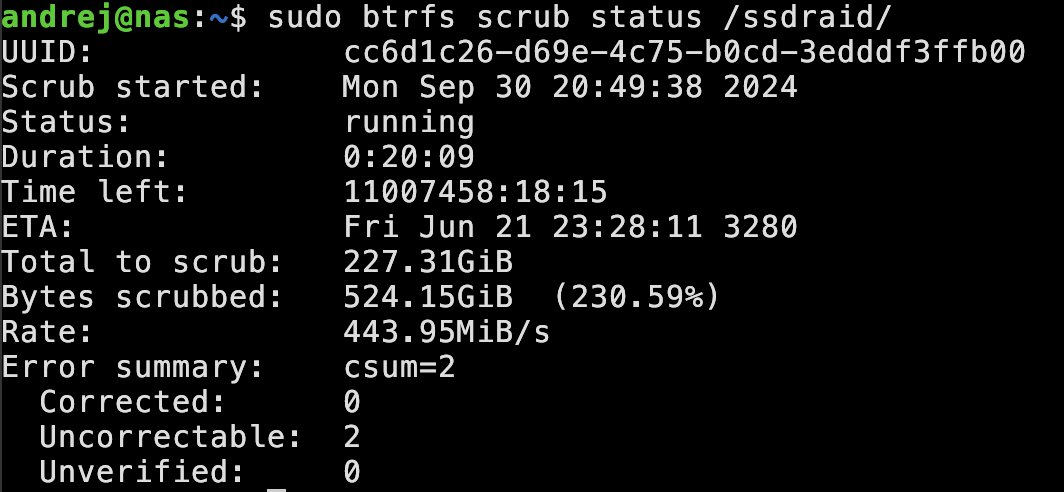
The output of the scrub is funny because BTRFS detected blocks that should have been deleted. 😵💫
Anyway. After the scrub has finished everything looks peachy again. THere are 2 uncorrectable errors though. These were in 2 files for the InfluxDB that is only for Home Assistant. I am not really using that, so that is fine.
However, I need to get some proper replacement drives for the SSD raid. My Mainboard has 2 M.2 slots unpopulated and that is what I will get. I do not need the PCIe speed but prices for the PCIe versions are actually better than the SATA versions for SSD.
So I am waiting now for the 2 NVMEs to arrive. Then I have to redo the server since that GPU is blocking access to one of those M.2 slots. I guess adding those 2 disks to the raid and then removing the other one will do the trick just fine. A yeah, and a bit of LUKS setup before with the keys and adding them to the /etc/crypttab for automounting.
Have a great day! 👋
