
Hey nerds 👋
As you may have read in the last blog post My first disk failure with BTRFS I lost an SSD. Here is the follow-up on what I had to do to replace those SSDs with my new M2 NVMEs.
Adding the disks - Proxmox annoyance
For myself I will document, where I put which SSD since I will not remember this, when the next will fail.
Here a short diagram of my mainboard, the MSI PRO Z690-A DDR4.
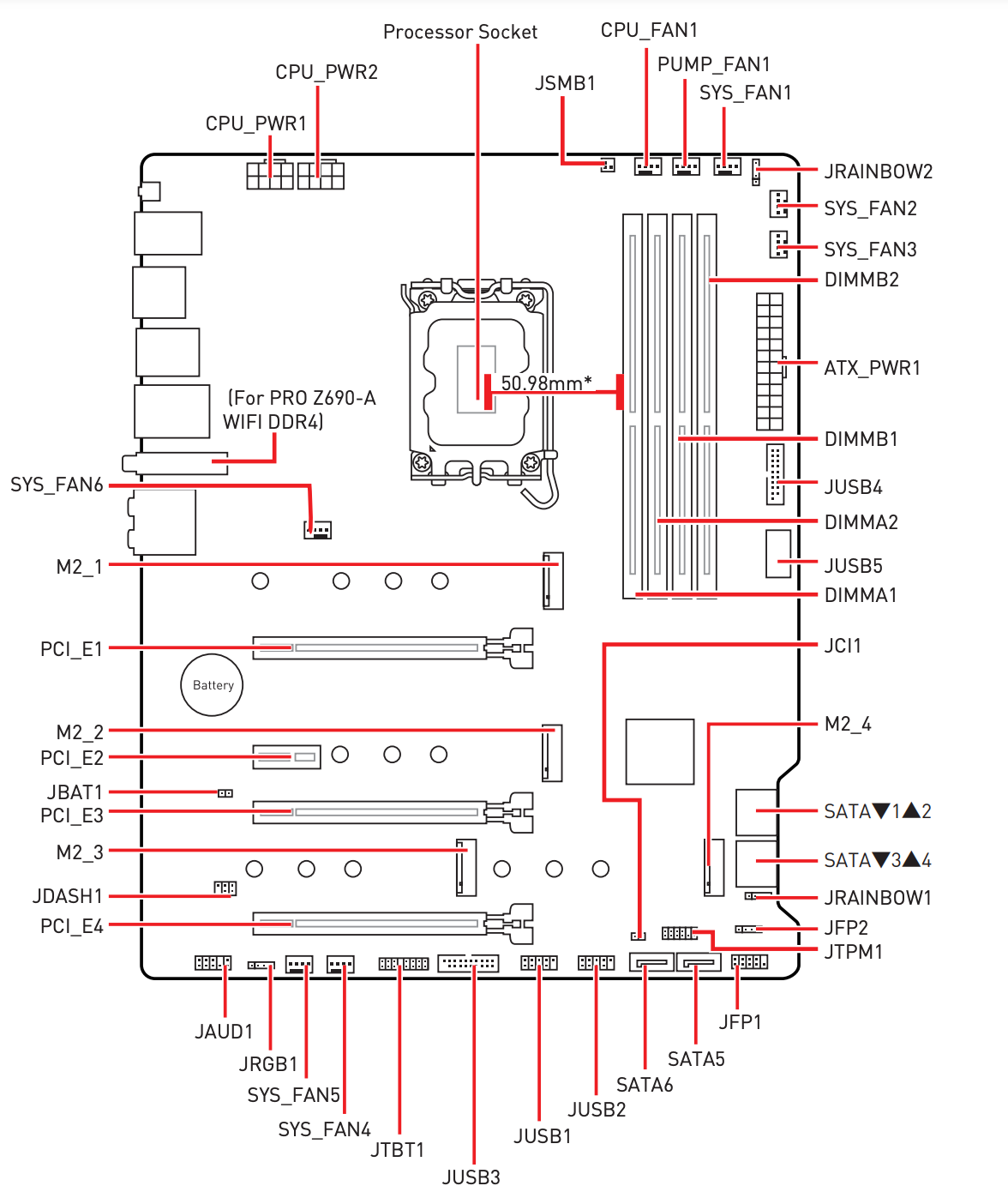
The slots below were already populated for Proxmox VM storage. Now I have added the 2 new ones as well. I checked the board docs before as well to verify I do not lose speed or something on the GPU. So here are my slots with the serial of the mapped SSD.
M2_1: 70B005D6pass through nas VMM2_2: 70B00681pass through nas VMM2_3: S69ENF0W951426JproxmoxM2_4: S69ENF0W951396Zproxmox
I lost one of the screws from the NVME drive and could not find it anymore in the case. I had to disassemble almost everything until I was able to find it. What hassle 😅
Since I disabled everything I thought noting down the HDDs serial from the top is a good idea for future me as well (pass through nas VM):
ZS800MA1ZLW279PAZLW22PX88DKW17XH
Adding those disks has already caused some problems with Proxmox. My NAS VM no longer boots. Figured it out quickly. Adding PCIe devices changes the numbering of some of them. My HBA card, which is passed through did have a new PCIe number and therefore was not found anymore. Adjusting that and adding the 2 new NVME drives did the trick.
My HBA was 0000:06:00 before. Now I added the 2 new NVMe drives they got
0000:02:000000:03:00
Now my HBA has 0000:08:00, okay whatever. Changed it and everything is good.
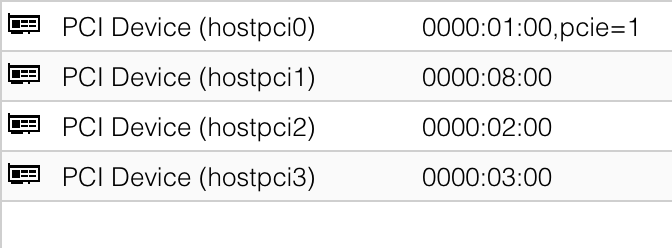
I would love to give those PCI Devices custom names. I will not remember what is what in a week or two. Did not find an option, though.
After that was settled, I could boot my NAS VM again.
Removing my old disks - A problem
Now let's tackle the actual issue. Trying to replace my old SSD and my backup HDD from the raid.
Adding devices was easy. I created a LUKS container again and added those drives to the /etc/crypttab for automatic encryption at boot time. Then a simple btrfs device add to the raid.
Now, removing was not that trivial. I could not remove my old disk with btrfs device remove
sudo btrfs device remove /dev/mapper/ssd-backup /ssdraid/
ERROR: error removing device '/dev/mapper/ssd-backup': Input/output errorA scrub showed me that I have two uncorrectable errors:
sudo btrfs scrub status /ssdraid
UUID: cc6d1c26-d69e-4c75-b0cd-3edddf3ffb00
Scrub started: Sun Oct 6 07:49:28 2024
Status: finished
Duration: 0:00:29
Total to scrub: 64.08GiB
Rate: 2.21GiB/s
Error summary: csum=2
Corrected: 0
Uncorrectable: 2
Unverified: 0Looking at the dmesg -T output, I could see the checksum errors. Looks like inluxdb index files are corrupted. I guess that happened because the container was running while the filesystem ran full. But that is just a guess.
[Sun Oct 6 07:49:32 2024] BTRFS warning (device dm-4): checksum error at logical 1500790784 on dev /dev/mapper/ssd_raid-1, physical 1500790784, root 257, inode 3305984, offset 0, length 4096, links 1 (path: influx/influx-data/engine/data/d397af7b60aa91c2/autogen/531/index/3/L3-00000008.tsi)
[Sun Oct 6 07:49:32 2024] BTRFS error (device dm-4): bdev /dev/mapper/ssd_raid-1 errs: wr 0, rd 0, flush 0, corrupt 29155121, gen 0
[Sun Oct 6 07:49:33 2024] BTRFS error (device dm-4): unable to fixup (regular) error at logical 1500790784 on dev /dev/mapper/ssd_raid-1
[Sun Oct 6 07:49:33 2024] BTRFS info (device dm-4): scrub: finished on devid 1 with status: 0
[Sun Oct 6 07:49:38 2024] BTRFS warning (device dm-4): checksum error at logical 1500790784 on dev /dev/mapper/ssd-backup, physical 1479819264, root 257, inode 3305984, offset 0, length 4096, links 1 (path: influx/influx-data/engine/data/d397af7b60aa91c2/autogen/531/index/3/L3-00000008.tsi)
[Sun Oct 6 07:49:38 2024] BTRFS error (device dm-4): bdev /dev/mapper/ssd-backup errs: wr 0, rd 0, flush 0, corrupt 45896582, gen 0
[Sun Oct 6 07:49:38 2024] BTRFS error (device dm-4): unable to fixup (regular) error at logical 1500790784 on dev /dev/mapper/ssd-backup
[Sun Oct 6 07:49:43 2024] BTRFS info (device dm-4): scrub: finished on devid 2 with status: 0dmesg -T from the scrub
After finding those errors, I also checked the filesystem with btrfs device check on all devices, but the filesystem itself was totally okay. It was just that one file.
Fixing influxdb index
After some research, I figured out how to do that. At least I believe that fixed everything. First, I deleted the file and then recreated the index again:
docker exec -it influx influxd inspect build-tsi --data-path /var/lib/influxdb2
?
You are currently running as root. This will build your
index files with root ownership and will be inaccessible
if you run influxd as a non-root user. You should run
build-tsi as the same user you are running influxd.
Are you sure you want to continue? Yes
2024-10-06T08:26:58.730759Z info Rebuilding bucket {"log_id": "0s4EryDW000", "name": "engine"}
2024-10-06T08:26:58.944877Z info Rebuilding retention policy {"log_id": "0s4EryDW000", "db_instance": "engine", "db_rp": "data"}
2024-10-06T08:26:58.944917Z info Rebuilding retention policy {"log_id": "0s4EryDW000", "db_instance": "engine", "db_rp": "replicationq"}
2024-10-06T08:26:58.944932Z info Rebuilding retention policy {"log_id": "0s4EryDW000", "db_instance": "engine", "db_rp": "wal"}Checking the filesystem on the path influx/influx-data/engine/data/d397af7b60aa91c2/autogen/531/index/3/ did show me new files.
A proper backup or snapshots would have been nice! Need to think about my non-existing backup strategy. 😅
Actually removing my disks
Now, the removal of the old disks did work without any issues.
sudo btrfs filesystem show /ssdraid/
Label: none uuid: cc6d1c26-d69e-4c75-b0cd-3edddf3ffb00
Total devices 2 FS bytes used 32.11GiB
devid 3 size 1.82TiB used 34.03GiB path /dev/mapper/m2_1
devid 4 size 1.82TiB used 34.03GiB path /dev/mapper/m2_2A final scrub to see if the errors are gone:
sudo btrfs scrub status /ssdraid/
UUID: cc6d1c26-d69e-4c75-b0cd-3edddf3ffb00
Scrub started: Sun Oct 6 12:33:48 2024
Status: finished
Duration: 0:00:19
Total to scrub: 64.39GiB
Rate: 3.39GiB/s
Error summary: no errors foundAnd a double check on the device stats as well:
sudo btrfs device stats /ssdraid/
[/dev/mapper/m2_1].write_io_errs 0
[/dev/mapper/m2_1].read_io_errs 0
[/dev/mapper/m2_1].flush_io_errs 0
[/dev/mapper/m2_1].corruption_errs 0
[/dev/mapper/m2_1].generation_errs 0
[/dev/mapper/m2_2].write_io_errs 0
[/dev/mapper/m2_2].read_io_errs 0
[/dev/mapper/m2_2].flush_io_errs 0
[/dev/mapper/m2_2].corruption_errs 0
[/dev/mapper/m2_2].generation_errs 0Nice. My fast raid is running again and even faster.
Conclusion
One thing I know for sure: This was Yak shaving at its best.
Any apparently useless activity which, by allowing one to overcome intermediate difficulties, allows one to solve a larger problem.

Problems often happen at the same time (disk full + corruption). Then you try to solve the initial problem but need to solve a bunch of other sometimes unrelated problems (Proxmox PCIe device numbering, PiKVM display output for MSI board, etc). If you do not know what work looks like in it, that is it. 100%! 😄
Anyway, I hope you had some fun. I know I did.
Let me hear from you if you encountered some Yak shaving yourself in your home lab. I can't be the only one!
Have a great day! 👋
